
 द्वारा द्वारा विनीत शुक्ला
द्वारा द्वारा विनीत शुक्ला
“डेटा एक कीमती चीज है और खुद सिस्टम से ज्यादा समय तक चलेगी। ” यह उद्धरण टिक बैरनर्स – ली, के आविष्कारक वर्ल्ड वाइड वेब, आज के दिन और युग में हमारी दुनिया की वास्तविकता को दर्शाता है।
तकनीकी प्रगति हमारे देखभाल वितरण को देखने के तरीके को बदल रही है। के आगमन के साथ आर्टिफिशियल इंटेलिजेंस (एआई .)), यंत्र अधिगम (एमएल), डीप लर्निंग, और एडवांस एनालिटिक्स, केयर गिवर्स तेजी से और अधिक सटीक निदान और उपचार प्रदान कर सकते हैं। हालांकि, कम लागत पर गुणवत्तापूर्ण देखभाल तक आसान पहुंच प्रदान करने के हमारे लक्ष्य में अभी भी कई बाधाएं हैं और उनमें से सबसे मौलिक सटीक और विश्वसनीय स्वास्थ्य डेटा तक पहुंच है।
जटिल बीमारियों की सहायता, निदान और उपचार के लिए एक एल्गोरिथम को प्रशिक्षित करने के लिए एक बड़े डेटाबेस की आवश्यकता होती है जिसमें सदस्य के संभावित शरीर रचना विज्ञान, विकृति और स्वास्थ्य जानकारी का पूरा स्पेक्ट्रम शामिल होता है। लेकिन बड़े जनसंख्या समूहों के बारे में इतनी विशाल और सटीक स्वास्थ्य जानकारी जुटाना मुश्किल है। बहुत सारी मूल्यवान जानकारी जो मौजूद है, गोपनीयता, नियामक, कानूनी और . के कारण पहुंच योग्य नहीं है नैतिक चुनौतियां डेटा शेयरिंग से जुड़ा है। यहीं पर फ़ेडरेटेड लर्निंग मॉडल गेम चेंजर हो सकते हैं।
पारंपरिक मशीन लर्निंग मॉडल के साथ चुनौतियां
आईडीसी के शोध से पता चलता है कि 2025 तक हेल्थकेयर डेटा 36 फीसदी सीएजीआर से बढ़ेगा। इसके अलावा, स्वास्थ्य देखभाल में, वैश्विक बड़े डेटा बाजार 2022 तक 22.07% सीएजीआर पर 34.27 अरब डॉलर तक पहुंचने की उम्मीद है। डेटा के इस शाब्दिक जलप्रलय को संभालना एक चुनौती होगी, प्रासंगिक और कार्रवाई योग्य अंतर्दृष्टि के लिए इसे खनन करने का उल्लेख नहीं करना।
स्वास्थ्य देखभाल संगठनों को जिन कुछ विशिष्ट बाधाओं का सामना करना पड़ सकता है उनमें विभिन्न संगठनों द्वारा डेटा के मिलान और विश्लेषण के लिए अपनाए जा रहे विभिन्न मानक शामिल हैं। साथ ही, डेटा अनुसंधान में निवेश करने वाले संगठन डेटा के प्रतिस्पर्धात्मक लाभ का पता लगाने की संभावना रखते हैं और डेटा साझा करने के लिए खुले नहीं हो सकते हैं।
डेटा तक पहुंच प्रदान करने में डेटा गोपनीयता और सुरक्षा नियमों की भी महत्वपूर्ण भूमिका होती है, इस तथ्य से प्रेरित होकर कि मरीज़ दुनिया भर में शोधकर्ताओं / स्वास्थ्य पेशेवरों के साथ अपने व्यक्तिगत चिकित्सा इतिहास को साझा करने में आशंका महसूस कर सकते हैं।
ऐसी स्थितियां पारंपरिक मशीन लर्निंग मॉडल को कम व्यवहार्य बनाती हैं क्योंकि यह मॉडल से जुड़ी निष्पक्षता और पूर्वाग्रह से जुड़ी जटिलताओं को पेश कर सकती है। इस तरह के एक सेटअप में, एक संगठन विभिन्न स्रोतों से एक केंद्रीय झील में डेटा एकत्र करेगा, इसका विश्लेषण करेगा, ताकि आबादी के लिए प्रासंगिक अंतर्दृष्टि प्राप्त की जा सके। उभरते हुए पैटर्न को जल्दी से खोजने के मामले में इस तरह के दृष्टिकोण में चुनौतियों का अपना सेट है। इसके अलावा, चूंकि डेटा साइलो में मौजूद है और नियामक कानूनों द्वारा संरक्षित है, यह डेटा की खंडित प्रकृति के कारण कम सटीक कार्रवाई योग्य नैदानिक परिणाम प्रदान करने की संभावना है।
फ़ेडरेटेड लर्निंग मॉडल क्या है और यह कैसे काम करता है?
फ़ेडरेटेड लर्निंग के तहत, एल्गोरिदम को डेटा सेट का आदान-प्रदान किए बिना, कई विकेन्द्रीकृत डेटा स्रोतों जैसे एज डिवाइस या स्थानीय डेटा नमूने रखने वाले सर्वर में प्रशिक्षित किया जाता है। चूंकि मॉडल कई स्थानों और मालिकों के डेटा पर जाता है, और विश्लेषण के लिए केवल कुछ मेटाडेटा खींचता है, डेटा की गोपनीयता और सुरक्षा बरकरार रहती है।
मॉडल एक पुनरावृत्त विधि पर काम करता है जिसमें सबसे हालिया संयुक्त मॉडल को स्थानीय नोड्स में वितरित किया जाता है और प्रत्येक नोड से अंतर्दृष्टि को फिर से संयुक्त मॉडल में एकत्रित किया जाता है। यह प्रक्रिया बार-बार दोहराई जाती है जिससे सर्वसम्मति मॉडल बनाने के लिए एल्गोरिदम को प्रशिक्षण दिया जाता है।
स्वास्थ्य देखभाल संगठनों के लिए इसका मतलब यह है कि, वे कई नियामक और गोपनीयता चिंताओं को दूर करने के अलावा, डेटा से कार्रवाई योग्य अंतर्दृष्टि प्राप्त कर सकते हैं, बिना स्रोत या स्वामित्व के, खरीद और भंडारण की लागत की चिंताओं को दूर कर सकते हैं।
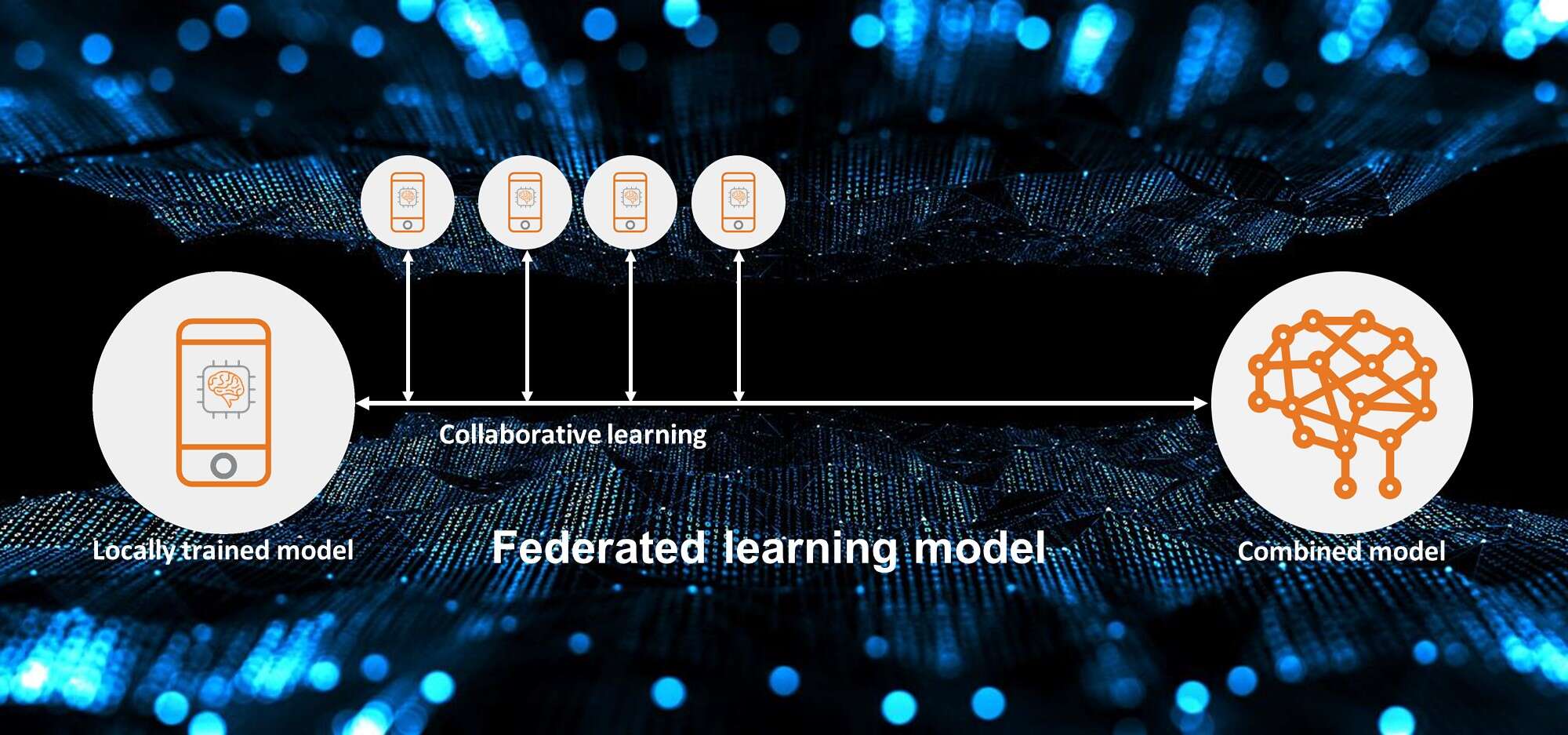
प्रशिक्षित मॉडल को विभिन्न स्वास्थ्य सेवा प्रदाताओं में साझा किया जा सकता है जो साझा मॉडल के शीर्ष पर अपना डेटा जोड़ सकते हैं और अंतिम मॉडल को एक आम सहमति मॉडल में समेटा जा सकता है जिसने प्रत्येक प्रदाता से ज्ञान प्राप्त किया है और इसलिए चिकित्सकीय रूप से अधिक सामयिक और प्रासंगिक है। ऐसा मॉडल जहां हम एक प्रदाता को समय पर मशीन इंटेलिजेंस के साथ बढ़ाते हैं, जैसे मामलों में स्वीकृति मिलने की संभावना है
- मरीजों के इलेक्ट्रॉनिक स्वास्थ्य रिकॉर्ड (ईएचआर) के आधार पर अस्पताल में भर्ती होने के जोखिम के निर्धारण के लिए भविष्य कहनेवाला डेटा विश्लेषण का उपयोग करना।
- तपेदिक या गुर्दे की बीमारी जैसे रोगों से पीड़ित होने की प्रवृत्ति या रोगों का शीघ्र पता लगाना
- जनसंख्या के विभिन्न वर्गों-लिंग, आयु, आनुवंशिक प्रोफ़ाइल आदि में दवा की प्रभावशीलता का पता लगाना।
फ़ेडरेटेड लर्निंग मॉडल के पेशेवरों और विपक्ष
फ़ेडरेटेड लर्निंग मॉडल कई लाभ प्रदान करते हैं
- वे किनारे के उपकरणों से सहयोगी सीखने की अनुमति देते हैं, जो प्रशिक्षण मॉडल के लिए एक विशाल डेटा सेट प्रदान करता है, बिना केंद्रीकृत सर्वर पर डेटा अपलोड करने या संग्रहीत करने की आवश्यकता के बिना, जो हार्डवेयर बुनियादी ढांचे की लागत बचाता है।
- चूंकि एज डिवाइस उपयोगकर्ताओं का व्यक्तिगत डेटा उनके अंत में रहता है, इसलिए डेटा सुरक्षा की सीमित चिंताएं हैं।
- वे स्थानीय वास्तविक समय की भविष्यवाणियों को भी सक्षम कर सकते हैं क्योंकि डेटा ट्रांसमिशन के कारण कोई अंतराल नहीं है।
हालांकि मॉडल चुनौतियों के अपने सेट के साथ आता है।
- मुख्य रूप से डेटा गुणवत्ता का मुद्दा है। चूंकि डेटा बड़ी संख्या में किनारे के उपकरणों पर रहता है, इसलिए विभिन्न विभिन्न स्रोतों से मॉडल के इनपुट को मानकीकृत करना अनिवार्य है।
- फ़ेडरेटेड लर्निंग मॉडल एज डिवाइस से आने वाले दुर्भावनापूर्ण/नकली डेटा से प्रभावित होने की अधिक संभावना है, जिसे “डेटा पॉइज़निंग” भी कहा जाता है।
हेल्थकेयर में फ़ेडरेटेड लर्निंग का भविष्य
डिजिटल स्वास्थ्य के क्षेत्र में नवाचारों की एक विस्तृत श्रृंखला को स्थापित करने के लिए फ़ेडरेटेड लर्निंग एक आशाजनक दृष्टिकोण है। केंद्रीकृत डेटा सेट की आवश्यकता के बिना एआई आधारित मॉडलों के सहयोगी प्रशिक्षण को सक्षम करके तकनीक पहले से ही बेहतर चिकित्सा छवि विश्लेषण से लेकर सहयोगी दवा खोज तक पूरे देखभाल वितरण चक्र में प्रभाव डाल रही है। कुल मिलाकर, यह क्षेत्र अभी भी विकसित हो रहा है, और अनुसंधान का एक सक्रिय क्षेत्र होगा। हालांकि इसमें लोगों को स्वस्थ जीवन जीने में मदद करने और स्वास्थ्य प्रणाली को सभी के लिए बेहतर बनाने में मदद करने की क्षमता है।
विनीत शुक्ला सीनियर डायरेक्टर हैं – डेटा साइंस एंड मशीन लर्निंग, ऑप्टम ग्लोबल सॉल्यूशंस (इंडिया) प्राइवेट। लिमिटेड
(अस्वीकरण: व्यक्त किए गए विचार पूरी तरह से लेखक के हैं और ETHealthworld.com आवश्यक रूप से इसकी सदस्यता नहीं लेता है। ETHealthworld.com प्रत्यक्ष या अप्रत्यक्ष रूप से किसी भी व्यक्ति/संगठन को हुए किसी भी नुकसान के लिए जिम्मेदार नहीं होगा)
.